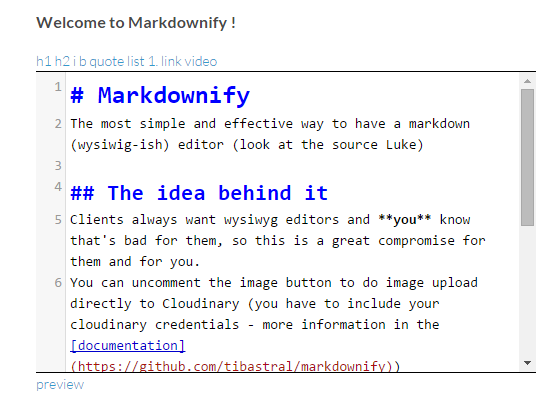
https://github.com/silentbicycle/sample ᔥ
Examples:
sample FILE # randomly choose & print 4 lines from
# file, in order
input | sample # same, from stream (file defaults to
# stdin)
sample FILE FILE2 FILE3 # randomly choose 4 lines between
# multiple input files
sample -n 10 FILE # choose 10 lines
sample -p 10 FILE # 10% chance of choosing each line
input | sample -p 5 # randomly print 5% of input lines
input | sample -d a,b,c # append input to files a, b, and c,
# even odds
input | sample -d a,b,c, # append input to files a, b, c, or
# /dev/null